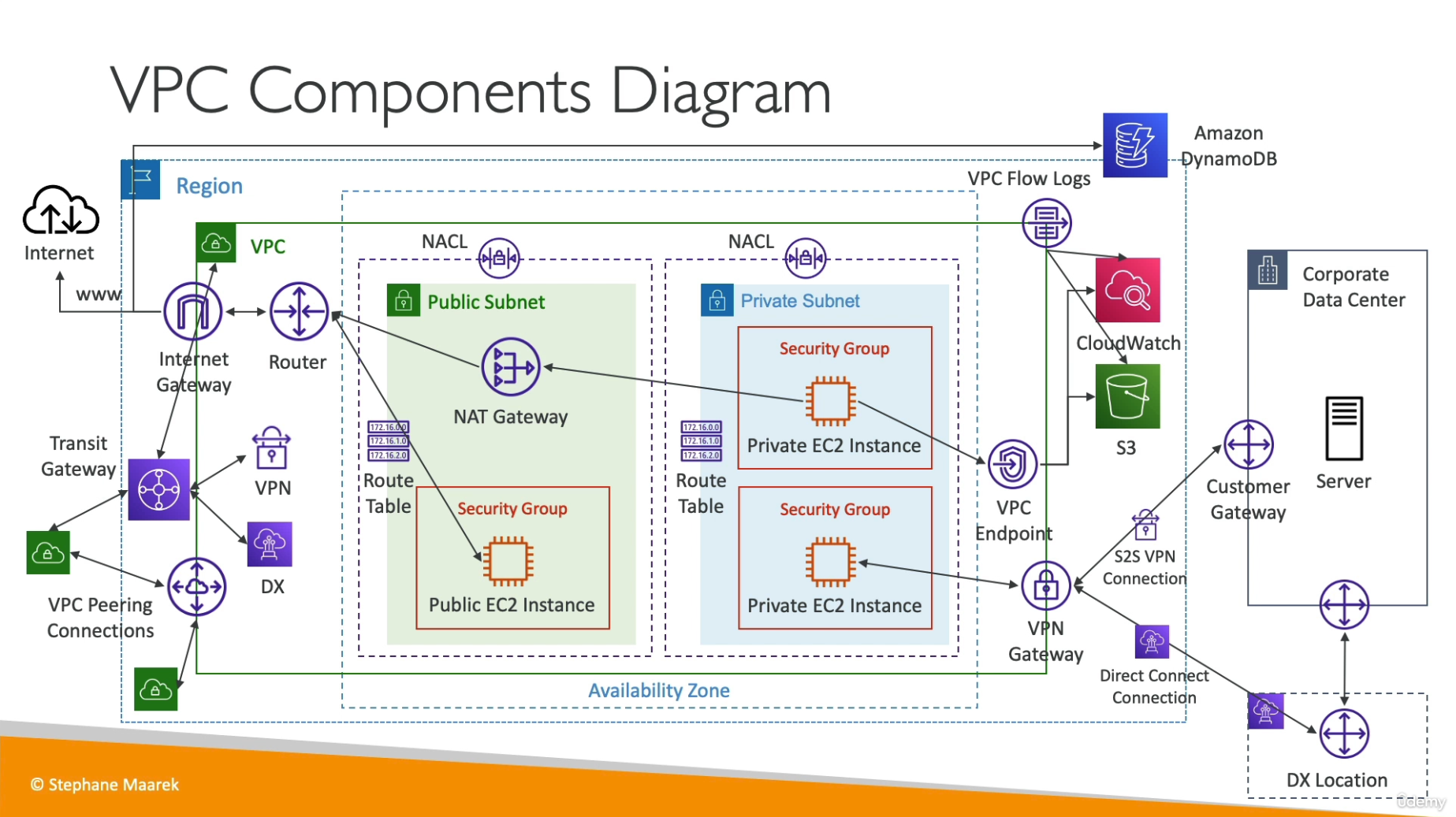
VPC Components Diagram

AWS Site-to-Site VPN
기업 데이터 센터를 AWS와 비공개로 연결하기 위해 기업은 고객 게이트웨이를 VPC는 VPN 게이트웨이를 갖춰야 함
공용 인터넷을 통해 사설 Site-to-Site VPN 연결
Site-to-Site VPN Connection
고객 게이트웨이가 있는 기업 데이터 센터와 가상 프라이빗 게이트웨이를 갖춘 VPC가 있음
온프레미스 고객에게 게이트웨이를 어떻게 구축해야 할까?
-> 고객 게이트웨이가 공용이라면 인터넷 라우팅이 가능한 IP 주소가 고객 게이트웨이 장치에 있음
고객 게이트웨이의 공용 IP를 사용해서 VGW와 CGW를 연결하면 됨
-> 고객 게이트웨이를 비공개로 남겨 사설 IP를 갖는 경우, 대부분 NAT-T를 활성화하는 NAT 장치 뒤에 있음
NAT 장치에 공용 IP가 있을 시 이 공용 IP를 CGW에 사용해야 함
+ 서브넷의 VPC에서 라우트 전파를 활성화해야 Site-to-Site VPN 연결이 실제로 작동함
+ 온프레미스에서 AWS로 EC2 인스턴스 상태를 진단할 때 보안 그룹 인바운드 ICMP 프로토콜이 활성화됐는지 확인해야 함(그렇지 않으면 연결되지 않음)
AWS VPN CloudHub
VGW를 갖춘 VPC가 있고, 고객 네트워크와 데이터 센터마다 고객 게이트웨이가 마련된 상황
Hands-on#0n - Site-to-Site VPN
1) create customer gateways
- Site-to-Site VPN 연결을 구성하기 위해서는 온프레미스 호스팅이 된 고객 게이트웨이가 필요하므로
- create Site-to-Site VPN connections ...
Direct Connect (DX)
원격 네트워크로부터 VPC로의 전용 프라이빗 연결을 뜻함
DX를 사용할 때는 전용 연결을 생성해야 하고, AWS DX 로케이션을 사용함
VPC에는 가상 프라이빗 게이트웨이를 설치해야 온프레미스 데이터 센터와 AWS 간 연결이 가능
설치 기간이 한 달보다 길어질 때도 있음
Direct Connect Gateway
다른 리전에 있는 하나 이상의 VPC와 연결할 경우
Direct Connect - Resiliency
복원력, 아키텍처 모드
핵심 워크로드의 복원력을 높이기 위해서는 여러 DX를 설치하는 것이 좋음
기업 데이터 센터가 2개이고 DX location도 둘일 때 중복이 발생 - 프라이빗 VIF가 하나 있는데 다른 곳에 또 있다면 하나의 연결을 여러 로케이션에 수립한 것이므로 DX 하나가 망가져도 다른 하나가 예비로 남아있기 때문에 복원력이 강해짐
핵심 워크로드 복원력을 최대로 끌어올리고 싶다면, (Maximum Resiliency for Critical Workloads)
각 DX location에 독립적인 연결을 두 개씩 수립하면 복원력을 최대로 만들 수 있음
Transit Gateway
네트워크 토폴로지 복잡성 문제로 만듦
IP Multicast할 때 사용
Transit Gateway: Site-to-Site VPN ECMP
Site-to-Site VPN 연결 대역폭을 ECMP를 사용해 늘리는 경우
- ECMP: Equal-cost multi-path, 여러 최적 경로를 통해 패킷을 전달하는 라우팅 전략
Transit Gateway: throughput with ECMP
VPN을 Transit Gateway로 연결하면 Site-to-Site VPN 하나가 여러 VPC에 생성됨 (동일한 Transit Gateway에 모두 전이적으로 연결되기 때문)
VPC - Traffic Mirroring
사례: 콘텐츠 검사, 위협 모니터링, 네트워킹 문제 해결
IPv6 Troubleshooting
IPv4는 VPC 및 서브넷에서 비활성화될 수 없음
IPv6가 활성화된 VPC가 있을 때, 서브넷에서 EC2 인스턴스를 실행할 수 없다고 하면 인스턴스가 IPv6를 받지 못해서가 아님 (실제로 공간이 크고 EC2 인스턴스를 위한 IPv6도 충분하기 때문)
-> 진짜 원인은 서브넷이나 VPC에 이용 가능한 IPv4가 없기 때문
-> solution: 서브넷에 IPv4 CIDR를 생성하는 것 (create a new IPv4 CIDR in your subnet)
Hands-on#0n -
1) VPC Edit CIDRs - Amazon-provided IPv6 CIDR block
2) Subnet - edit IPv6 CIDRs > subnet CIDR block
3) Subnet - edit subnet settings > auto-assign IP settings: Enable auto-assign IPv6 address
4) Instance (BastionHost) - networking: Manage IP addresses > eth0: IPv6 addresses Auto-assign
5) 해당 instance security group edit inbound rules - add SSH IPv6
6) Route tables - Public routes > IPv6 target: local로 설정되어 있음
Egress-only Internet Gateway
송신 전용 인터넷 게이트웨이, NAT Gateway와 비슷하지만 IPv6 전용
Hands-on#0n - Egress only internet gateway
1) create egress only internet gateway (DemoEIGW)
2) private route tables edit routes - ::/0, eggress only internet gateway
-> 사설 서브넷의 EC2 인스턴스가 IPv6로 인터넷에 액세스하지만 인터넷에는 도달하지 못함
VPC Section Summary
01. CIDR: IP Range
02. VPC: virtual private cloud, IPv4와 IPv6를 위해 작동함
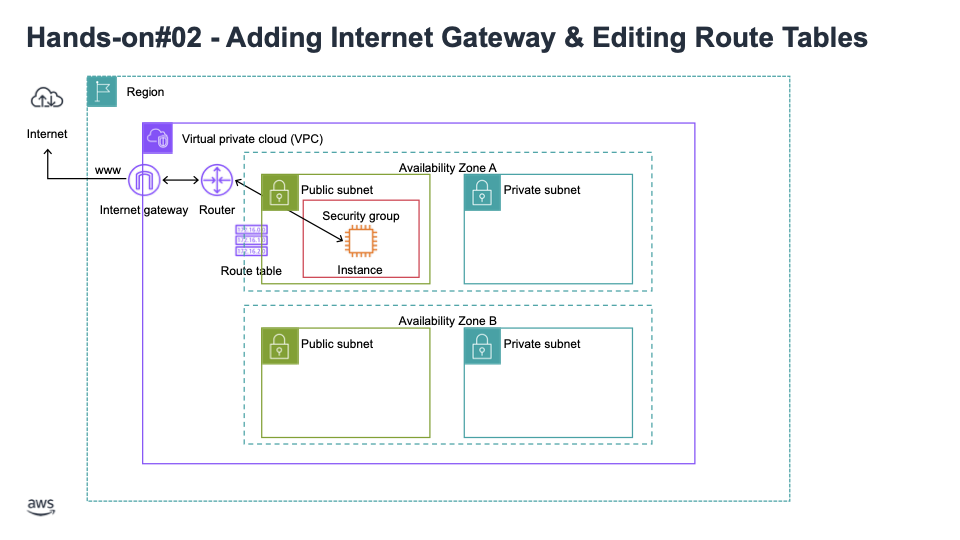
03. Subnets: CIDR를 정의하는 AZ에 연결됨, public/private
04. Internet Gateway: at the VPC level, public subnet은 인터넷 게이트웨이 연결시키고, 퍼블릭 서브넷에서부터 인터넷 게이트웨이로 경로 생성
05. Route Tables: 네트워크가 VPC 내에서 흐르도록 하는 키, 수정됨, 인터넷 게이트웨이 경로들, VPC Peering connections, VPC Endpoints 등 포함
06. Bastion Host: SSH에 들어갈 수 있는 public EC2 instance, 비공개 서브넷의 다른 EC2 인스턴스들과 SSH 연결
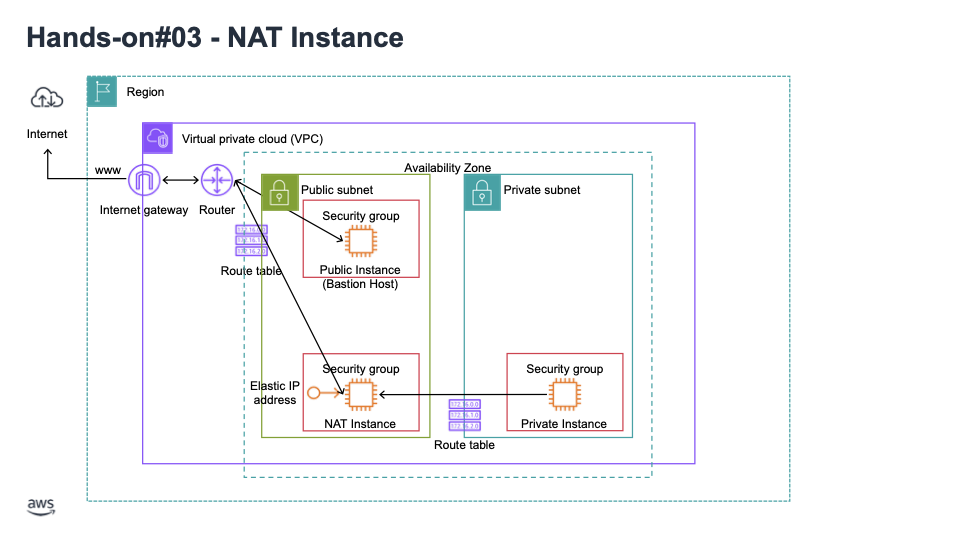
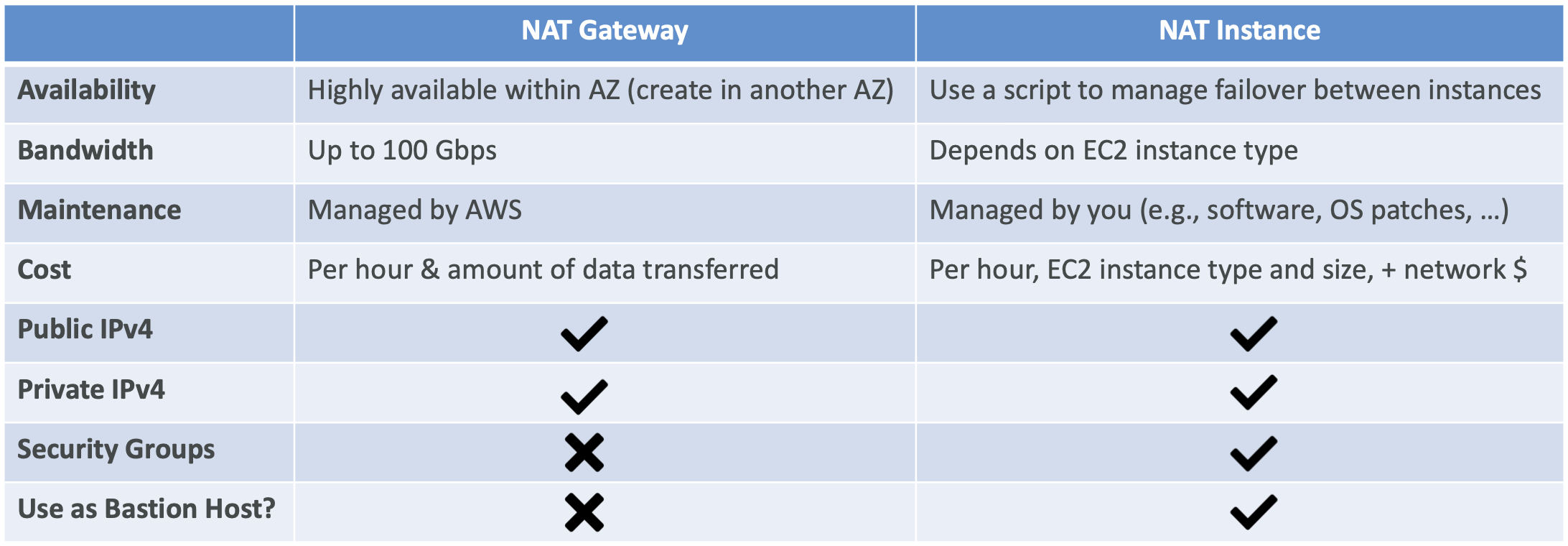
07. NAT Instances: 퍼블릭 서브넷에 배포된 EC2 인스턴스, 프라이빗 서브넷의 EC2 인스턴스에게 인터넷 접근을 제공, 오래되었고 사용이 권장되지 않고 있기 때문에 소스 / 대상 확인 플래그를 비활성화해야 함 (그렇게 해야 작동을 할 것이고 보안 그룹 규칙을 수정할 수 있음)
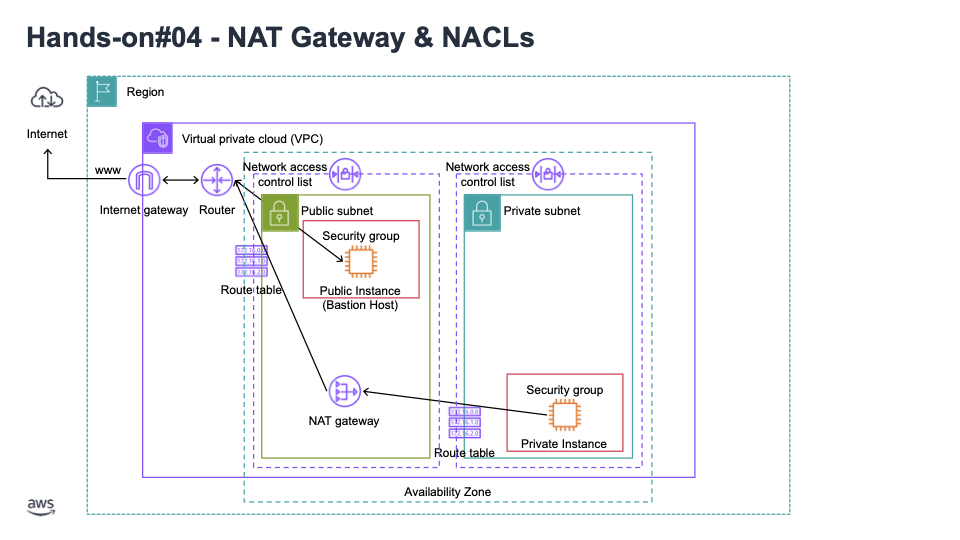
08. NAT Gateway: 프라이빗 EC2 인스턴스에 확장 가능한 인터넷 접근을 제공하고, 요청의 타켓이 IPv4 주소일 때 사용
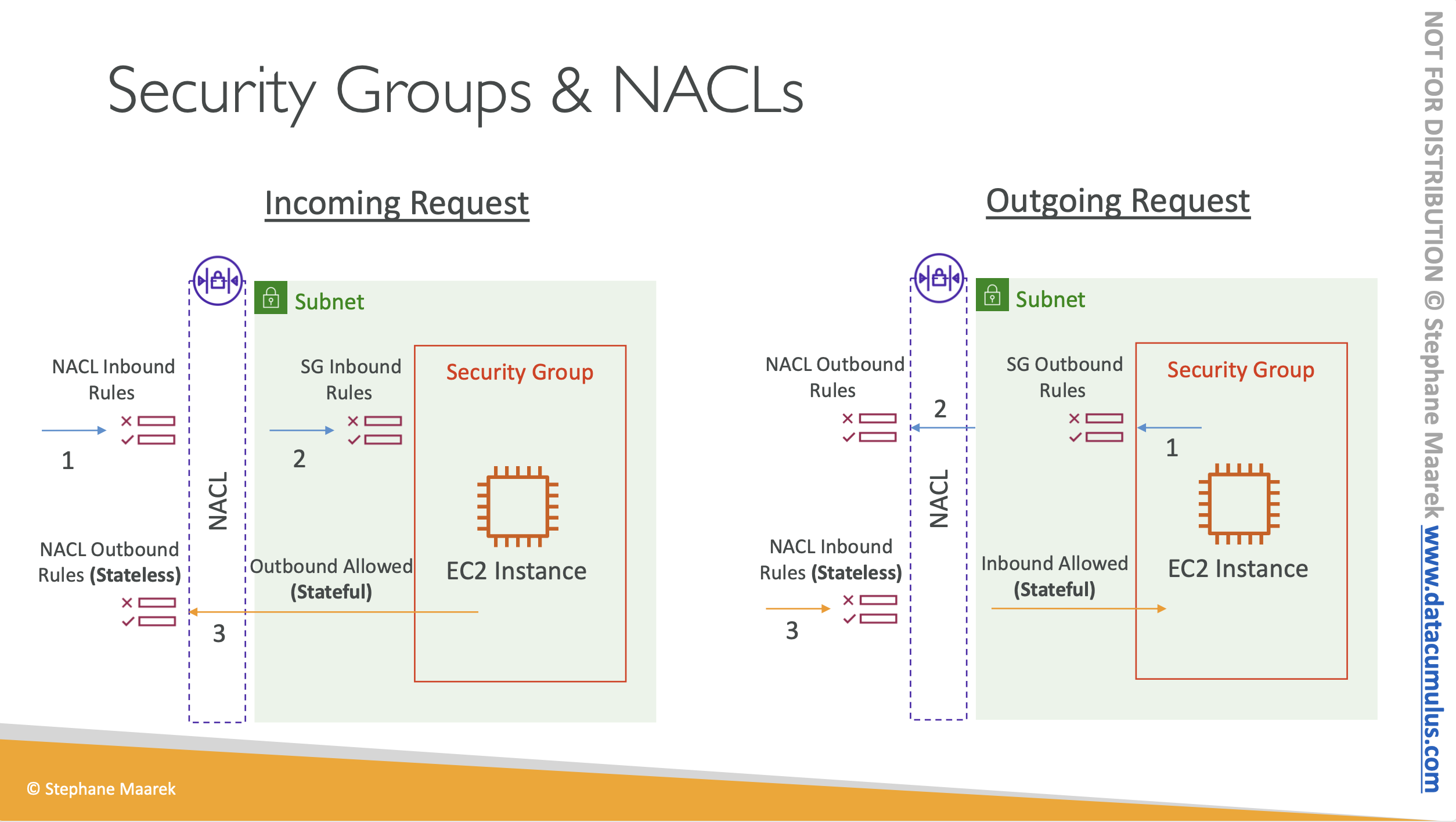
09. NACL: 네트워크 ACL, 서브넷 레벨에서 인바운드와 아웃바운드 접근을 정의하는 방화벽 규칙, stateless 상태라 인바운드와 아웃바운드 규칙은 항상 평가되고 있음
10. Security Groups: Stateful 상태 - 인바운드가 허용되었을 경우 아웃바운드도 자동적으로 허용되고 그 반대도 마찬가지, 보안 그룹 규칙은 EC2 인스턴스 레벨에 적용됨
11. VPC Peering: 두 개의 VPC를 연결, 겹치지 않는 CIDR을 가지는 경우에 해당, VPC 피어링 연결은 비전이적 (따라서 세 개의 VPC를 연결하고자 한다면 세 개의 VPC 피어링 연결이 필요함)
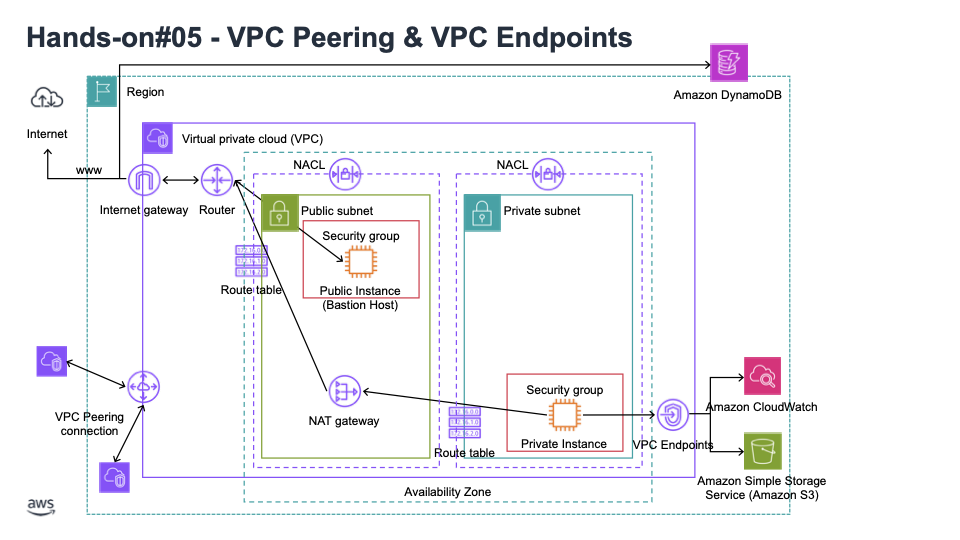
12. VPC Endpoints: 프라이빗 접근을 허용 - VPC 내의 AWS 서비스라면 Amazon S3, DynamoDB, CloudFormation, SSM 등 무엇이든 가능 (Amazon S3와 DynamoDB에는 게이트웨이 엔드포인트가 있는 것도 보았고 나머지는 모두 인터페이스 엔드포인트)
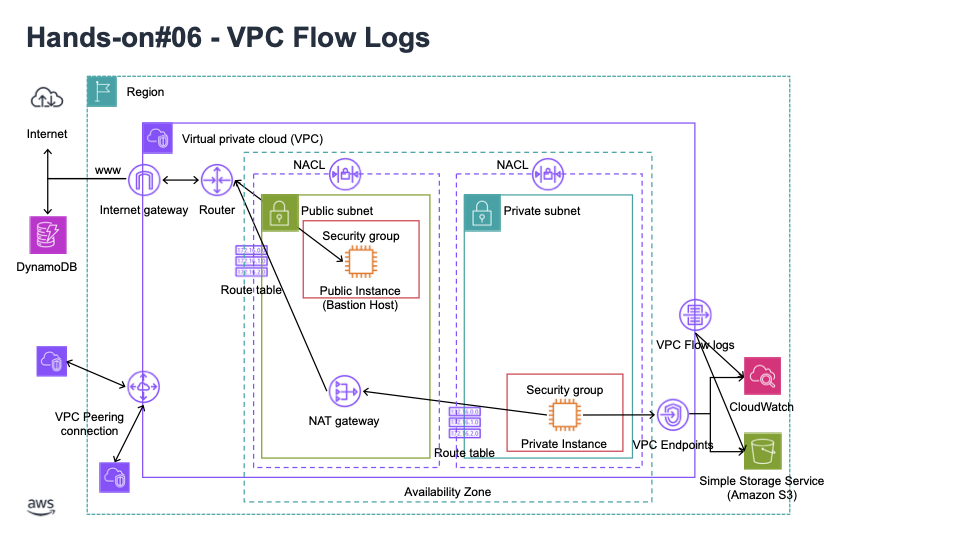
13. VPC Flow Logs: VPC 내의 모든 패킷에 관련된 로그 레벨의 메타데이터를 갖는 데 가장 좋은 방법, 허용과 비허용 트래픽과 관련된 정보도 조금 있음, VPC 서브넷이나 ENA 레벨에서 생성 (Amazon S3로 전송되어 분석되고 Athena에서 분석될 수 있었으며, CloudWatchLogs로 전송되어 CloudWatchLog Insights를 통해 분석될 수도 있었음)
VPC를 데이터 센터로 연결하기 위한 두 가지 방법
14. 1) Site-to-Site VPN: 공공 인터넷을 통한 VPN 연결이기 때문에 AWS에 버추얼 비공개 게이트웨이를 생성해야 하고 데이터 센터에 고객 게이트웨이를 생성하고 그 후에 VPN 연결을 설립, 여러개의 VPN 연결을 설립할 때 같은 virtual private gateway를 사용하면 VPN CloudHub를 사용해서 hub-and-spoke VPN모델을 만들어 사이트들을 연결할 수 있기도 함
15. 2) Direct Connect: 연결이 완전히 프라이빗 상태, 공공 인터넷을 통하지 않지만 설립하는 데에 시간이 소요됨, 데이터 센터를 Direct Connect 위치로 연결해야 작동함 (더 복잡하지만 더 보안적으로 안전함, 연결도 안정적)
16. Direct Connect Gateway: 다른 AWS 리전의 많은 VPC와 Direct Connect를 만들기 위한 것
17. AWS PrivateLink / VPC Endpoint Services: 고객 VPC에 직접 생성한 VPC 내에서 서비스로 비공개적으로 연결하기 위한 것, 좋은 점은 VPC 피어링이나 공공 인터넷이나 NAT 게이트웨이나 라우팅 테이블을 요구하지 않음, 주로 Network Load Balancer와 ENI와만 사용됨 - VPC 내의 서비스를 네트워크를 노출시키지 않고 수백, 수천개의 고객 VPC에게 노출시킬 수 있도록 함
18. ClassicLink: EC2-Classic 인스턴스를 VPC로 비공개로 연결하기 위한 것, 사용이 권장되지 않음
19. Transit Gateway: VPC, VPN, 그리고 Direct Connect를 위한 전송 피어링 연결
20. Traffic Mirroring: 네트워크 트래픽을 ENI에서 복사하여 분석을 하는 것
21. Egress-only Internet Gateway: NAT Gateway와 비슷하지만 IPv6 트래픽이 인터넷 밖으로 가는 것을 위한 것
Networking Costs in AWS per GB - Simplified
첫번째 AZ에 EC2 인스턴스가 있을 경우 EC2 인스턴스로 향하는 트래픽은 무료
같은 가용영역 내 두 EC2 인스턴스 간 트래픽은 사설 IP로 통신할 시 무료
같은 리전 내 다른 두 AZ에 있는 EC2 인스턴스 두 개가 소통하기 위해 공용 IP나 탄력적 IP를 사용하는 경우, 청구 비용은 GB당 2센트(사설 IP를 사용할 경우 반으로 절감)
References
Udemy, Ultimate AWS Certified Solutions Architect Associate SAA-C03, Section 27
'Networking > AWS' 카테고리의 다른 글
| [AWS] ANS-C01#01: ELB (0) | 2024.07.19 |
|---|---|
| AWS products (0) | 2024.07.10 |
| [AWS] SAA-C03#09: VPC lab(2) (0) | 2024.07.02 |
| [AWS] SAA-C03#08: VPC lab(1) (0) | 2024.06.28 |
| [AWS] SAA-C03#07: ELB & ASG (0) | 2024.06.25 |