장점 연속적인 최적화: SGD는 연속적인 최적화를 통해 합성 데이터를 생성할 수 있어, 쿼리 결과에 대한 차이가 최소화된다. 확장성: 대규모 데이터셋에서도 효과적으로 작동한다.
유연성: 다양한 데이터셋과 쿼리 유형에 적용할 수 있다. 단점 수렴 문제: 학습률(lr)과 같은 하이퍼파라미터에 민감하며, 잘못 설정된 경우 수렴하지 않을 수 있다. 비선형 관계: 데이터의 비선형 관계를 다루는 데 한계가 있을 수 있다.
2. Multiplicative Weights Update (MWU) Mechanism
MWU 메커니즘은 적응적으로 쿼리를 선택하고, 각 쿼리의 응답을 업데이트하는 방법이다. 이 방법은 데이터의 각 레코드에 가중치를 할당하고, 각 쿼리 응답에 따라 가중치를 업데이트한다. 장점 적응적 쿼리 선택: 가장 정보가 많은 쿼리를 선택하여 효율성을 높인다. 프라이버시 보호: 프라이버시 예산을 효율적으로 사용한다. 단점 복잡성: 구현이 복잡하고, 계산 비용이 높을 수 있다. 적용 범위 제한: 일부 특정 쿼리 유형에만 효과적일 수 있다.
3. High-Dimensional Matrix Mechanism (HDMM)
HDMM은 고차원 데이터에 대해 최적화된 방식으로 쿼리를 처리하는 메커니즘이다. 쿼리 집합에 대한 응답을 선형 결합으로 표현하고, 이를 통해 최적의 노이즈 추가 방법을 찾아낸다. 장점 고차원 데이터 처리: 고차원 데이터셋에 대해 효과적으로 작동한다. 최적화된 노이즈 추가: 노이즈 추가를 최적화하여 정확도를 높인다. 단점 계산 복잡성: 계산 비용이 높아 대규모 데이터셋에 적용하기 어려울 수 있다. 제한된 쿼리 유형: 일부 쿼리 유형에 제한적일 수 있다.
4. Projected Gradient Descent (PGD)
PGD는 경사 하강법을 사용하는 투영 메커니즘 중 하나로, 최적화 과정에서 정규화 제약 조건을 적용한다. 이는 주어진 제약 조건 내에서 최적의 해를 찾는 데 효과적이다. 장점 정확도: 제약 조건 내에서 최적화하므로, 정확한 결과를 얻을 수 있다. 제약 조건 적용: 다양한 제약 조건을 쉽게 적용할 수 있다. 단점 수렴 문제: 학습률과 같은 하이퍼파라미터에 민감하며, 잘못 설정된 경우 수렴하지 않을 수 있다. 복잡성: 구현이 복잡할 수 있다.
5. Local Sensitivity Sampling (LSS)
주요 개념
국소 민감도 (Local Sensitivity): 특정 데이터셋에서 특정 쿼리에 대한 민감도를 계산한다. 이는 데이터셋의 특정 부분에서 쿼리 결과의 변동성을 측정한다. 노이즈 추가: 민감도에 따라 적절한 노이즈를 추가하여 프라이버시를 보호한다. 장점 효율적 노이즈 추가: 국소 민감도를 사용하여 보다 효율적으로 노이즈를 추가할 수 있다. 높은 정확도: 민감도에 맞춰 노이즈를 추가함으로써 데이터의 유용성을 유지한다. 단점 복잡성: 민감도를 계산하는 과정이 복잡할 수 있다. 특정 쿼리에 맞춤: 특정 쿼리에 대해 민감도를 계산하므로, 모든 유형의 쿼리에 적용하기 어려울 수 있다.
6. Private Gaussian Mechanism (PGM)
PGM은 Gaussian 노이즈를 추가하여 차등 프라이버시를 보장하는 메커니즘이다. Gaussian 노이즈는 데이터의 평균을 중심으로 정규 분포를 따르는 노이즈를 추가한다. 주요 개념 글로벌 민감도 (Global Sensitivity): 데이터셋 전체에서 특정 쿼리에 대한 민감도를 계산한다. 이는 데이터셋에서 최악의 경우에 쿼리 결과가 얼마나 변할 수 있는지를 측정한다. Gaussian 노이즈: 정규 분포를 따르는 노이즈를 추가하여 프라이버시를 보호한다. 장점 프라이버시 강화: Gaussian 노이즈를 사용하여 데이터의 민감한 정보를 효과적으로 보호할 수 있다. 적용 범위: 다양한 유형의 데이터셋과 쿼리에 적용할 수 있다. 단점 노이즈 크기: 글로벌 민감도를 기준으로 노이즈를 추가하므로, 데이터셋의 크기와 민감도에 따라 노이즈가 커질 수 있다. 데이터 유용성: 노이즈가 커질수록 데이터의 유용성이 떨어질 수 있다.
7. PrivBayes
PrivBayes는 차등 프라이버시를 보장하는 베이지안 네트워크 기반의 합성 데이터 생성 기법이다. 원본 데이터의 분포를 학습하고, 그 분포를 기반으로 합성 데이터를 생성한다. 장점 정확한 데이터 생성: 원본 데이터의 통계적 특성을 잘 반영한 합성 데이터를 생성할 수 있다. 유용성: 다양한 데이터 분석 및 머신러닝 모델 학습에 사용할 수 있다. 단점 복잡성: 베이지안 네트워크 학습과 파라미터 추정 과정이 복잡하고 계산 비용이 높을 수 있다. 스케일링 문제: 매우 큰 데이터셋에 적용하기 어려울 수 있다.
8. DualQuery
DualQuery는 차등 프라이버시를 보장하는 데이터 쿼리 응답 기법이다. 이 방법은 데이터의 중요한 통계적 쿼리에 대한 정확한 응답을 제공하기 위해 노이즈를 적응적으로 조절한다.
장점 높은 정확도: 적응적 노이즈 조절을 통해 정확한 쿼리 응답을 제공할 수 있다. 적응성: 중요도가 높은 쿼리에 더 적합한 노이즈 수준을 선택할 수 있다. 단점 복잡성: 적응적 노이즈 조절 및 쿼리 선택 과정이 복잡하고 계산 비용이 높을 수 있다. 제한된 쿼리 응답: 특정 유형의 쿼리에 대해서만 적용할 수 있다.
MWEM은 차등 프라이버시를 보장하면서 데이터의 분포를 추정하기 위한 기법이다. 이 방법은 데이터의 가중치를 반복적으로 업데이트하여 실제 데이터 분포에 가까운 분포를 생성한다.
주요 개념 Multiplicative Weights: 데이터의 각 레코드에 가중치를 할당하고, 반복적으로 업데이트한다. Exponential Mechanism: 쿼리 응답에 노이즈를 추가하여 차등 프라이버시를 보장한다. 장점 정확한 분포 추정: 반복적인 업데이트를 통해 실제 데이터 분포에 가까운 분포를 생성할 수 있다. 적응성: 다양한 쿼리 유형에 대해 적용할 수 있다. 단점 계산 비용: 반복적인 가중치 업데이트 과정이 복잡하고 계산 비용이 높을 수 있다. 수렴 문제: 반복 과정에서 수렴하지 않을 위험이 있다.
상황별추천
대규모 데이터셋:
SGD: 확장성이 좋고, 대규모 데이터셋에서 효과적으로 작동한다. PGD: 제약 조건이 있는 최적화 문제에 효과적이다.
고차원 데이터셋:
HDMM: 고차원 데이터에 최적화된 방식으로 쿼리를 처리한다.
적응적 쿼리 응답:
MWU: 적응적 노이즈 조절로 높은 정확도를 유지할 수 있다. DualQuery: 중요한 쿼리에 대한 높은 정확도를 유지할 수 있다.
프라이버시 보호와 데이터 유용성:
MWEM: 반복적인 업데이트를 통한 정확한 분포 추정이 가능한다. PrivBayes: 원본 데이터의 통계적 특성을 잘 반영한 합성 데이터를 생성할 수 있다.
복잡한 조건부 의존성 처리:
PrivBayes: 베이지안 네트워크를 사용하여 복잡한 조건부 의존성을 처리할 수 있다.
PrivBayes: 원본 데이터의 통계적 특성을 잘 반영한 합성 데이터를 생성할 수 있지만, 계산 비용이 높다. DualQuery: 적응적 노이즈 조절을 통해 높은 정확도의 쿼리 응답을 제공하지만, 구현이 복잡할 수 있다. MWEM: 다양한 쿼리 유형에 적용할 수 있으며, 반복적인 업데이트를 통해 정확한 분포를 추정할 수 있지만, 계산 비용이 높을 수 있다.
상위호환 관계
1. SGD < PGD
제약 조건을 추가하여 최적화 문제를 해결할 수 있다.
- PGD: 제약 조건을 적용한 경사 하강법, 데이터의 특정 조건을 만족해야 하는 최적화 문제에 적합하다.
2. Laplace < Gaussian Mechanism
고차원 데이터에 적합, 델타 파라미터 사용하여 노이즈를 추가한다.
3. MWU < MWEM
쿼리 응답과 데이터 분포 추정에 대해 더 복잡하고 정밀한 업데이트를 수행한다.
4. LSS < PGM
국소 민감도를 사용하여 노이즈 추가하는 방식에서, 글로벌 민감도를 기반으로 Gaussian 노이즈를 추가한다.
설명: 각 범주를 이진 벡터로 변환한다. 각 벡터는 하나의 1과 나머지 0으로 구성된다. 장점: 단순하고 직관적, 범주 간 순서나 크기를 가정하지 않음 단점: 차원이 높아질 수 있음, 범주가 많을 경우 메모리 사용량이 증가함 적합성: 많은 노이즈를 추가해야 하는 경우가 많아질 수 있으며, 고차원 데이터는 계산 복잡도를 증가시킬 수 있다.
2. 레이블 인코딩 (Label Encoding)
설명: 각 범주를 고유한 정수로 매핑한다. 장점: 단순하고 메모리 효율적, 차원이 증가하지 않음 단점: 범주 간 순서나 크기를 가정하게 되어 모델이 이를 잘못 해석할 수 있음 적합성: 범주 간의 순서나 크기 정보가 노출될 수 있어 적합하지 않을 수 있다.
3. 순서 인코딩 (Ordinal Encoding)
설명: 범주형 데이터를 순서가 있는 정수로 변환한다. 장점: 순서가 있는 데이터를 잘 표현할 수 있음, 메모리 효율적 단점: 범주 간의 거리를 동일하게 가정, 범주 간 순서가 중요하지 않은 경우 부적절할 수 있음 적합성: 순서가 중요한 경우 유용하지만, 범주 간 순서 정보가 노출될 수 있어 적합하지 않을 수 있다.
4. 바이너리 인코딩 (Binary Encoding)
설명: 각 범주를 고유한 숫자로 매핑하고, 이 숫자를 이진수로 변환한다. 장점: 차원이 원핫 인코딩보다 낮음, 원핫 인코딩과 레이블 인코딩의 중간 정도의 복잡도와 메모리 사용량을 가짐 단점: 복잡도가 증가할 수 있음, 일부 정보가 손실될 수 있음 적합성: 차원이 적당히 낮고, 범주 간의 순서 정보가 직접적으로 노출되지 않아 적합하다.
바이너리 인코딩은, 차원 감소: 원핫 인코딩보다 낮은 차원을 가지므로 계산 복잡도가 줄어든다. 정보 노출 최소화: 범주 간의 순서나 크기 정보가 직접적으로 노출되지 않는다. 프라이버시 보호: 적당한 수준의 노이즈를 추가하여 프라이버시를 보호할 수 있다.
목차 1. 객체지향 프로그래밍 2. 클래스와 인스턴스 1) 클래스 정의 2) 클래스 생성 3) 필드(field) 4) 메서드(method) 5) self: 메서드가 가져야 할 첫 번째 매개변수 6) 인스턴스(instance) 7) 인스턴스의 필드와 메서드 3. 왜 객체지향 프로그래밍인가? 1) 상속 2) 다형성 4. 이후 학습이 필요한 내용
class Tree:
height = 0
leaf_size = 0
...
class CherryBlossom(Tree): #Tree의 성질을 그대로 계승
height = 25 # 벚꽂나무에 맞게 값을 재조정
leaf_size = 1
# 마치 부모와 자식처럼 코드를 관리 가능
# 현실 세계의 객체 구조와 유사
Point III 다형성 : 같은 이름의 코드가 다양한 역할을 하는 것
class CherryBlossom(Tree):
height = 25
leaf_size = 1
class Mugunghwa(Tree):
height = 1
leaf_size = 5
# 같은 height, leaf_size 변수가 있지만
# class마다 가지는 값이 다름
# 같은 이름으로 각 객체의 값을 관리할 수 있음
목차 1. 모듈 - 변수와 함수, 코드를 모아둔 하나의 .py파일 1) 모듈 불러오기 - import ① math: 수학 연산 ② random: 랜덤한 숫자를 선택 2) 모듈 사용하기 - . + 모듈 속 함수/변수 3) 모듈 만들기 - .py 확장자 2. 패키지 - 모듈을 폴더 단위로 관리하는 것 - from A import func: 불러올 장소(A) 와 불러올 변수/함수(func)를 명시한 것 - 폴더(디렉토리)와 모듈로 구성되는 세트
option key를 누르고, 커서 드래그 이후 좌우 방향키 이용하여 사용하지 않는 코드 삭제(혹은 생성 가능)
// User
@IBOutlet weak var userThumbnail: UIImageView!
@IBOutlet weak var userNickName: UILabel!
@IBOutlet weak var userLocation: UILabel!
@IBOutlet weak var userTemperature: UILabel!
// Item
@IBOutlet weak var itemThumbnail: UIImageView!
@IBOutlet weak var itemInfoTitle: UILabel!
@IBOutlet weak var itemInfoDescription: UILabel!
KingFisher import하여 image 적용
상세뷰 우측 상단에 아이콘 삽입
DetailViewController의 viewDidLoad 함수에 configureNavigationBar() 추가
Cocoa Touch Class 생성(Class: ItemInfoCell, Subclass of: UICollectionViewCell)
//
// HomeViewController.swift
// CarrotHomeTab
//
// Created by sehee on 2022/08/24.
//
import UIKit
import Combine
// - 홈의 뷰 모델 만들기(리스트 가져오고, 아이템 탭 했을 때의 행동 정의)
// - 뷰 모델은 리스트 가져오기
class HomeViewController: UIViewController {
@IBOutlet weak var collectionView: UICollectionView!
let viewModel: HomeViewModel = HomeViewModel(network: NetworkService(configuration: .default))
var subscriptions = Set<AnyCancellable>()
override func viewDidLoad() {
super.viewDidLoad()
configureCollectionView()
bind()
viewModel.fetch()
}
private func configureCollectionView() {
}
private func bind() {
viewModel.$items
.receive(on: RunLoop.main)
.sink { items in
//self.applyItems(items)
print("--> update collection view \(items)")
}.store(in: &subscriptions)
viewModel.itemTapped
.sink { item in
let sb = UIStoryboard(name: "Detail", bundle: nil)
let vc = sb.instantiateViewController(withIdentifier: "DetailViewController") as! DetailViewController
//vc.viewModel = DetailViewModel(network: NetworkService(configuration: .default), itemInfo: item)
self.navigationController?.pushViewController(vc, animated: true)
}.store(in: &subscriptions)
}
}
Snapshot 설정하여 내부 페이지 확인
오류 수정 #1
Thread 1: "[<CarrotHomeTab.ItemInfoCell 0x7fd8d7846620> setValue:forUndefinedKey:]: this class is not key value coding-compliant for the key descriptionLable."
→ Xcode 내 코드에 연결시킨 button을 찾을 수 없음
뷰 내의 인스펙터가 연결 코드 정보와 상이하여 발생(연결 이후 라벨을 변경한 경우, Lable → Label)
ItemInfoCell 내 연결정보 변경
class ItemInfoCell: UICollectionViewCell {
@IBOutlet weak var thumbnail: UIImageView!
@IBOutlet weak var titleLabel: UILabel!
@IBOutlet weak var descriptionLabel: UILabel!
@IBOutlet weak var priceLabel: UILabel!
@IBOutlet weak var numOfChatLabel: UILabel!
@IBOutlet weak var numOfLikeLabel: UILabel!
그래도 불가...
Referencing Outlets 해당 부분을 x
오류 수정 #2
Thread 1: Fatal error: Unexpectedly found nil while implicitly unwrapping an Optional value
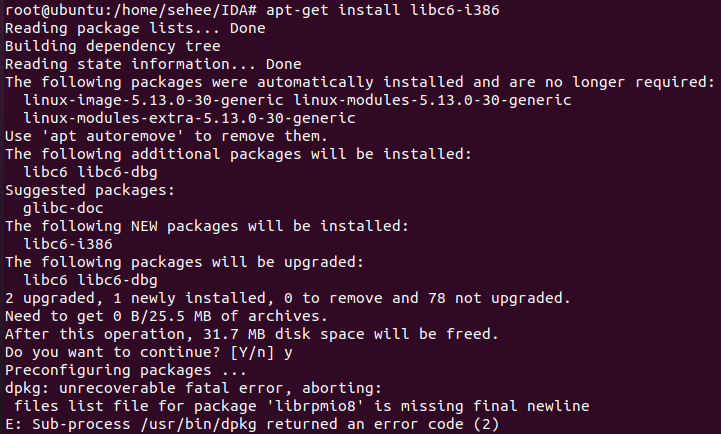
dpkg: unrecoverable fatal error, aborting: files list file for package 'librpmio8' is missing final newline E: Sub-process /usr/bin/dpkg returned an error code (2)
Try to fix it with
# rm /var/lib/dpkg/info/libopenjp2*
# dpkg --configure -a
# apt update
# apt upgrade
After that run Plesk update fix with:
# plesk installer --select-release-current --reinstall-patch --upgrade-installed-components